主页 > 下载安卓版imtoken钱包 > 以太坊设计原则
以太坊设计原则
译自:
尽管以太坊的很多想法已经在比特币等更早的加密货币上实施和测试了 5 年,但以太坊处理某些协议功能的方式与通常的方式仍然存在许多差异。 很多时候,以太坊会被用来构建全新的经济方法,因为它有很多其他系统没有的功能。 本文将详细描述以太坊的所有潜在优势以及构建以太坊协议过程中的一些争议点。 此外,还将指出我们的方案和替代方案的潜在风险。

原则
以太坊协议的设计遵循以下原则:
1.三明治复杂模型
我们认为以太坊的底层协议应该越简单越好,接口设计应该通俗易懂,那些无法避免的复杂部分应该放在中间层。 中间层不是核心共识的一部分,对最终用户是不可见的。 它包括:高级语言编译器、参数序列化和反序列化脚本、存储数据结构模型、leveldb存储接口和wire协议。 当然,这样的设定并不是绝对的。
2. 自由
不应限制用户使用以太坊协议,也不应试图支持或不支持某些以太坊合约或交易。 这类似于“网络中立”概念背后的指导原则。 比特币交易协议不遵循这个原则。 在比特币交易协议中,不鼓励将区块链用于“去标记”目的(例如,数据存储、元协议)。 在某些情况下,对对齐协议的显式修改可能允许犯罪分子以未经授权的方式使用区块链来攻击应用程序。 因此,在以太坊中,我们强烈建议设置交易费用,用户使用区块链的步骤越多,交易费用就越多(类似于庇古税)。 这样交易手续费就可以作为对合法矿工的奖励,不法分子也可以付出代价,一石二鸟。
3.概括
以太坊协议的属性和操作码应该最大化低级概念(如基本粒子),以便它们可以随意组合。 因此,通过剥离那些不需要的功能,低级概念变得更加高效。 遵循这一原则的一个例子是我们选择 LOG 操作码作为向 dapps 提供信息的方式,而不是像以前那样记录所有交易和消息信息。 在早期,“消息”的概念完全是多个概念的集合,其中包括“函数调用”和“外部观察者感兴趣的事件”,并且两者是完全分离的。
4.没有特色就是最大的特色点
为了遵循泛化原则,我们拒绝将那些高级用例作为协议的一部分嵌入,即使是经常使用的用例,也从不这样做。 如果真的想实现这些用例,可以在合约中创建子协议(例如,基于以太坊的子货币、比特币/莱特币/狗狗币侧链等)。 例如,以太坊缺乏类似于比特币的“时间锁定”功能。 但是这个功能可以通过下面的协议来模拟:用户将一个签名的数据包发送给特定的合约进行处理,如果数据包在特定的合约中有效,则执行相应的功能。
5、无风险规避机制
如果增加的风险带来实质性的好处(例如,广义状态转换、出块时间提高 50 倍、共识效率),我们愿意承担更高的风险。
这些原则指导着以太坊的发展,但并不是绝对的; 在某些情况下,为了减少开发时间或者不想一下子做太多的改动,也会让我们延迟做某些改动,保存起来以备以后的版本去修改。
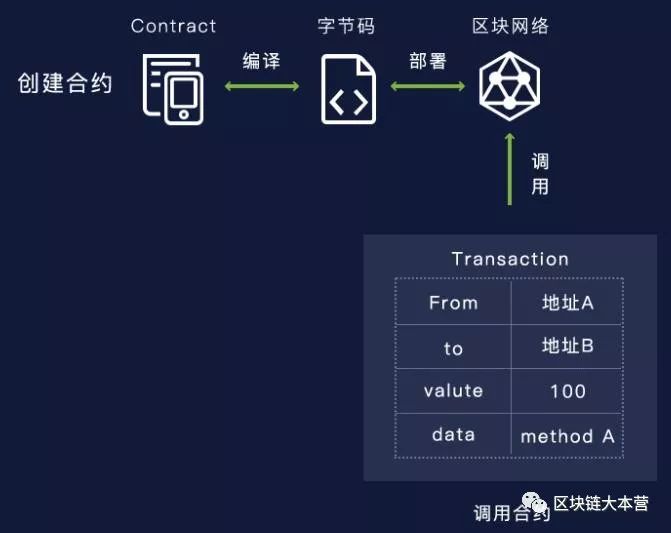
区块链层协议
本节介绍以太坊区块链层协议的变化,包括区块和交易如何工作,数据如何序列化和存储,以及账户背后的机制。
账户,不是UTXO①
比特币及其众多衍生品将用户的余额信息存储在 UTXO 结构中,系统的整个状态由一系列“有效输出”组成(你可以将这些“有效输出”想象成硬币)。 每个 UTXO 都有一个所有者和它自己的值属性。 一笔交易在消费若干个UTXO的同时,会产生若干个新的UTXO。 “有效输出”必须满足以下约束条件:
1. 每个引用的输入必须有效且未使用;
2. 交易的签名必须与每个输入的所有者的签名相匹配;
3. 输入的总值必须等于或大于输出的总值。
因此,在比特币系统中,一个用户的“余额”是该用户的私钥可以有效签名的所有UTXO的总和。 下图展示了比特币系统中的交易输入输出过程:

不过,以太坊放弃了UTXO方案,转而采用更简单的方法:利用状态(state)的概念来存储一系列账户,每个账户都有自己的余额,以及以太坊特定的数据(代码或内存)。 如果交易发起人的账户余额足以支付交易费用,则交易有效,相应的金额将从发起人的账户中扣除并记入接受账户。 在某些情况下,如果接受的账户中有需要执行的代码,交易会触发代码的执行,那么账户的内部记忆可能会发生变化,甚至可能会创建额外的信息并发送到其他账户,导致新的A事务发生。
虽然以太坊没有采用 UTXO 的概念,但是 UTXO 有一些优点:
1.更高程度的隐私保护
如果用户对每笔交易都使用新地址,则很难链接帐户。 这适用于对安全性要求高的货币系统,但不适用于任何dapp应用。 因为dapps通常需要跟踪用户复杂的绑定状态,dapps的状态不能像货币体系中的状态那样简单划分。
2. 潜在的可扩展性
UTXO 理论上更具可扩展性。 因为我们只能依靠那些金融货币拥有者来维护能够证明货币所有权的 Merkle 树,即使每个人(包括数据拥有者)都忘记了某个数据,真正受损的也只有数据拥有者。 其他人不受影响。
在以太坊账户体系中,如果 Merkle 树中某个账户对应的信息被所有人丢失,那么该账户将无法处理任何可能影响它的消息,包括发送给它的消息。
但是UTXO并不是唯一可以扩展的,还有一种不依赖UTXO进行扩展的方式(这里不做扩展,译者注)。
该帐户的好处如下:
1.节省大量空间
如果一个账户有 5 个 UTXO,则从 UTXO 模式切换到账户模式所需的空间将从 300 字节减少到 30 字节。 具体计算如下:
300 = (20+32+8)*5(20为地址字节数,32为TX id字节数,8为交易金额值字节数);
30 = 20 + 8 + 2(20为地址字节数,8为交易值字节数,2为nonce②字节数)
但是实际节省的并没有那么大,因为账户需要存储在Patricia树中。 此外,以太坊中的交易比比特币小(以太坊为 100 字节,比特币为 200-250 字节),因为每笔交易只需要生成一个引用、一个签名和一个输出。
2. 更高的可替代性
在UTXO结构中,“有效输出”的源代码实现中没有区块链层的概念,所以无论是技术上还是法律上,通过建立红名单/黑名单,根据这些“有效输出”的来源来区分输出”它们不是很实用。
3.简单
以太坊编码更简单、更容易理解,尤其是当涉及到复杂的脚本时。 虽然任何去中心化应用程序都可以使用 UTXO 来实现,但这种方法本质上是通过给脚本一种方法来限制给定 UTXO 可以使用和请求的 UTXO 类型来实现的,包括脚本评估的应用程序更改根。 Merkle 树状态证明。 因此,UTXO 的实现要比以太坊使用账户的方式复杂得多。
4.轻客户端
轻客户端可以通过指定方向扫描状态树,随时访问与账户相关的所有数据。 在UTXO方法中,引用随着每笔交易而变化,这对于使用上述UTXO根状态传播机制的长时间运行的dapp应用来说无疑是沉重的负担。
我们相信账户的好处远远超过其他选择,特别是对于我们正在处理的包含任意状态和代码的 dapp。 此外,本着“没有特色就是最大特色”的指导原则,我们认为如果用户真的很在意隐私,可以使用合约中的签名包协议来构建一个加密“混合器”进行加密。
账户方式的一个弱点是,为了防止重放攻击,每笔交易都必须有一个nonce,这就使得账户需要跟踪nonce的使用情况,只有在nonce最后一次使用且值为1时才接受交易。这意味着即使不再使用的帐户也无法从帐户状态中删除。 解决这个问题的一个简单方法是让交易包含一个块号,使它们在几个时间段内唯一,并在每个时间段重置 nonce。 由于全面扫描账户的开销太大,为了删除未使用的账户,矿工或用户需要“ping”它们。 我们在1.0上没有实现这个机制,1.1及以上版本可能会用到这个机制。
默克尔帕特里夏树
Merkle Patricia 树/trie,由 Alan Reiner 构想并在 Ripple 协议中实现,是以太坊的主要数据结构,用于存储所有账户状态,以及每个区块中的交易和收据数据。 MPT 是 Merkle 树和 Patricia 树组合的缩写。 通过组合这两棵树创建的结构具有以下属性:
1、每个唯一的键值对唯一映射到根的哈希值; 在 MPT 中,不可能只用一对键值对来欺骗成员(除非攻击者有 ~2^128 的计算能力);
2. 键值对的增删改查时间复杂度是对数的。
MPT 为我们提供了一个高效、易于更新的“指纹”,代表了整个状态树。
MPT更详细的描述:
MPT的具体设计决策如下:
1.有两种类型的节点
KV节点和离散节点。 KV节点的存在提高了效率,因为如果树在特定区域是稀疏的,KV节点可以作为“捷径”来代替深度为64的树。
2.离散节点是十六进制的,不是二进制的
这使得查找更有效率,我们现在意识到这个选择并不理想,因为十六进制树的查找效率可以通过批量存储节点来模拟二进制。 MPT 树的结构实现非常容易出错,最终至少会导致状态根不匹配。
3.空值和非会员没有区别
这样做是为了简化逻辑,以太坊中没有设置的值默认为0,空字符串也用0表示。但是需要强调的是,这牺牲了一些通用性,因此不是最优的。
4.终端节点和非终端节点的区别
技术上不需要标识一个节点是否为终端节点,因为以太坊中所有的树都是用来存储静态密钥长度的,但是为了增加通用性,我们还是会加上这个标识,以期以太坊方的MPT实现可以被其他加密货币采用。
5、在安全树中使用SHA3(k)作为秘钥(在状态树和账户存储树中使用)
使用 SHA3(k),通过将离散节点的链深度设置为 64,并反复调用 SLOAD 和 SSTORE 指令,对于那些试图对树进行 DoS 攻击的人来说变得非常困难。 然而,这也使得树的节点难以穷尽。 如果你想让你的客户端有穷举的能力,最简单的方法就是维护一个数据库映射:sha3(k) -> k
RLP
RLP(recursive length prefix):递归长度前缀。
RLP 编码是以太坊中的主要序列化格式,无处不在:区块、交易、账户状态和有线协议消息。 具体见RLP官方说明:
RLP 旨在成为一种高度简化的序列化格式,其唯一目的是存储嵌套字节数组③。 与 protobuf 和 BSON 等现有解决方案不同,RLP 没有定义任何指定的数据类型,例如 Boolean、floa、double 或 integer。 它只是将结构存储为嵌套数组,并将其留给协议来确定数组的含义。 RLP 也不明确支持地图集合。 半官方的建议是使用[[k1, v1], [k2, v2], ...]的嵌套数组来表示键值对集合,k1, k2 ...按照字符字符串的标准排序。
和RLP功能相同的一个方案是protobuf或者BSON,都是一直在用的算法。 然而,在以太坊中,我们更喜欢使用 RLP,因为:
1、易于实施;
2、绝对保证字节的一致性。
很多语言的map集合没有明确的排序,浮点数格式有很多特例,可能导致相同数据的编码和hash值不同。 通过在内部开发协议,我们可以确保在设计时考虑到这些目标(这是一个通用原则,也适用于代码的其他部分,例如 VM)。 BitTorrent 使用的编码方法 bencode 可能是 RLP 的替代方法。 但它采用十进制编码方式,略逊于二进制RLP。
压缩算法

有线协议和数据库都使用自定义压缩算法来存储数据。 该算法可以描述为:length-length编码④值为0,同时保留其他值(除一些特殊情况如sha3('')),示例如下:
>>> compress('horse')
'horse'
>>> compress('donkey dragon 1231231243')
'donkey dragon 1231231243'
>>> compress('\xf8\xaf\xf8\xab\xa0\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xbe{b\xd5\xcd\x8d\x87\x97')
'\xf8\xaf\xf8\xab\xa0\xfe\x9e\xbe{b\xd5\xcd\x8d\x87\x97'
>>> compress("\xc5\xd2F\x01\x86\xf7#<\x92~}\xb2\xdc\xc7\x03\xc0\xe5\x00\xb6S\xca\x82';{\xfa\xd8\x04]\x85\xa4p")
‘\xfe\x01'在压缩算法出现之前,以太坊协议中很多地方都有一些特例。 比如sha3经常被覆盖,所以sha3(' ')=' ',这样就节省了64个字节,没有把code存入账户。 不过最近,这些导致以太坊数据结构臃肿的特例都被去掉了,取而代之的是,在区块链协议之外的层,即 wire 协议及其 Insert user database 实现中加入了数据保存功能。 这增加了模块化,简化了共识层,并使压缩算法能够不断更新以相对容易地部署。
树(trie)的使用
以太坊区块链中的每个区块头都包含指向三棵树的指针:状态树、交易树和收据树。
状态树表示访问区块后的整个状态;
交易树代表了区块中的所有交易,这些交易以index为key进行索引; (比如k0:第一个执行的事务,k1:第二个执行的事务)
收据树代表每笔交易对应的收据。 交易收据是一个RLP编码的数据结构:
[medstate, gas_used, logbloom, 日志]
在:
• medstate:事务处理完成后,树根的状态;
• gas_used:交易处理后使用的gas量;
• 日志:是[地址、[主题1、主题2...]、数据] 形式的元素列表。 该表由事务执行过程中调用的操作码LOG0...LOG4生成(包括主调用和子调用); address 是生成日志主题的合约地址,最多四个 32 字节的值; 数据是任意字节大小的数组;
• logbloom:Bloom filter⑤ 由事务中所有日志的地址和主题组成。
区块头中还有一个布隆过滤器,它是区块中所有交易的布隆过滤器的逻辑或。 这种结构使得以太坊协议轻客户端的使用尽可能友好。
叔块(废弃块)奖励
2013年10月,Josena和Tel Aviv首先提出的GHOST协议是一项了不起的创新。 这是加速块生成时间的第一次认真尝试。 因为区块在网络中传播需要一定的时间,如果矿工A挖出一个区块并向全网广播,广播途中B也挖出这个区块,则B的区块已经过时,并且B 的这种挖矿对网络的安全没有贡献。 GHOST 的目的是解决过时挖矿导致安全性降低的问题。
另外还有一个中心化问题:如果A是矿池30%的算力,B有10%的算力。 A 有 70% 的时间产生过时区块(因为另外 30% 的时间会产生最新的区块,所以它会立即挖掘数据),而 B 有 90% 的时间产生过时区块。 如果出块的时间间隔很短,淘汰率会变高,A会以更大的算力让挖矿更有效率。 因此,如果出块速度过快,很容易造成网络算力大的矿池控制挖矿过程。
据 Josenna 和 Tel Aviv 介绍,GHOST 在计算哪条链是最长链的过程中解决了过时区块导致的网络安全性下降问题。 即不仅是父块和更早的块,叔块⑥也被加入计算哪个块具有最大的工作量证明。
为了解决第二个问题:中心化问题,我们采用了不同的策略:对过时区块也提供区块奖励:挖出一个过时区块的奖励是该区块基础奖励的7/8; 区块的侄子区块将获得基础奖励的 1/32 作为赏金。 但是,交易费用不会奖励给叔叔块或侄子块。
在以太坊中,过期分叉上7代以内的相对区块可以称为过期区块。 造成这种限制的原因在于以太坊中有几类账户,首先,如果GHOST协议不限制废弃块的数量,它会在计算废弃块的有效性上花费大量的开销; 其次,对废弃区块的无限激励政策,会让矿工失去主要的链上挖矿热情; 最后,计算表明,第 7 层内过时的区块奖励政策限制提供了大部分预期效果,而没有负面影响。
区块时间算法的设计决策包括:
• Block time 12s:选择12s是因为这已经是最快的时间了,基本上比网络延迟还长。 在 2013 年一篇关于测量比特币网络延迟的论文中,确定 12.6 秒是新生成的区块传播到 95% 节点的时间; 然而,该论文还指出传播时间与块大小成正比,因此在更快的货币中,我们可以预期传播时间会大大减少。 传播间隔恒定在大约 2 秒。 然而,为了安全起见,在我们的分析中,我们假设块需要 12 秒来传播。
• 限制7 个祖先块:这种设计的目的是只保留少量块并清除较早的块。 七个块已被证明可以提供大多数所需的效果。
• 1个后代块的限制:例如c(c(p(p(p(p(head))))) c=child, p = parent是非法的,因为它有两个后代块。这样设计的目的是为了简单起见,上面的模拟结果表明它不会带来很大的中心化风险。
• **叔块必须是有效的:**叔块必须是有效的头部,而不是有效的块。 这样做也是为了简单起见,将区块链模型保持为线性数据结构。 但是,要求叔块是有效块也是合法的。
• 奖励分配:基础挖矿奖励7/8分配给叔块,1/32分配给侄块,交易手续费为0%。 如果费用占主导地位,从中心化的角度来看,这将使叔块激励失效; 然而,这就是为什么只要我们继续使用 PoW,以太坊就会继续发行以太币。
难度更新算法
目前,以太坊通过以下规则进行难度更新:
diff(genesis) = 2^32
diff(block) = diff.block.parent + floor(diff.block.parent / 1024) *
1 if block.timestamp - block.parent.timestamp < 9 else
-1 if block.timestamp - block.parent.timestamp >= 9难度更新规则的设计目标如下:
• 快速更新:区块之间的时间应随着哈希算力的增减而快速调整;
• 低波动性:如果算力恒定,难度应该不会剧烈波动;
• 简单:算法的实现应该比较简单;
• 低内存:算法不应依赖过多的历史区块,并尽可能少地使用“内存变量”。 假设有最新的十个区块,加上这十个区块头部存储的内存变量,这些区块就可以用于算法的计算;
•非开发性:算法不应该给矿工太多的能力去篡改时间戳或矿池,重复增加或删除算力,以最大化他们的利益。
我们目前的算法对于低波动性和非开发来说并不理想,至少我们计划切换时间戳来比较父块和祖父块,因此矿工只有在连续挖掘 2 个块时才会有动力修改时间戳。 另一个更强大的模拟公式:
天然气和费用
比特币中的所有交易都大致相同,因此可以对它们的网络成本进行建模。 以太坊中的交易更为复杂,因此交易费用需要考虑账户的诸多方面,包括带宽成本、存储成本和计算成本。 尤其重要的是,以太坊编程语言是图灵完备的,因此交易使用任意数量的带宽、存储和计算成本。 这可能会导致成本计算过程中突然断电,计算被迫暂停。
以太坊交易费用的基本机制如下:
• 每笔交易必须指定一定数量的gas(即指定startgas的值),并支付每单位gas所需的费用(即gasprice)。 在交易开始执行时,startgas * gasprice 的以太价值将从发送者账户中扣除;
• 交易执行过程中的所有操作,包括读写数据库、发送消息、每一步计算都会消耗一定的gas;
• 如果交易完成,消耗的gas值小于指定的limit值,交易正常执行,剩余的gas值赋值给变量gas_rem; 交易完成后,发送方将收到返回的gas_rem * 以太坊的gasprice值,矿工的奖励为(startgas - gas_rem)* gasprice 价值的以太币;
• 如果gas在交易执行过程中耗尽,所有的执行都会恢复到原来的状态,但是交易仍然有效,除了交易的唯一结果是支付给矿工startgas * gasprice的价值在以太坊中,另一个保持不变;
• 当一个合约向另一个合约发送消息时,可以对该消息引起的子执行设置gas 限制。 如果子执行用完 gas,子执行会恢复,但 gas 仍然会被消耗。
必须满足以上几点,例如:
• 如果交易没有指定gas limit,那么恶意用户可以发送具有数十亿步循环的交易。 没有人可以处理这样的交易,因为处理它可能需要很长时间,以至于无法提前通知网络上的矿工,这将导致拒绝服务漏洞。
• 严格的气体计数、时间限制等的替代方法行不通,因为它们太主观了
• startgas * gasprice 的全部值应该在一开始就设置好,这样交易就不会在交易执行过程中因为gas不足而终止。 请注意,仅仅检查账户余额是不够的,因为账户可以将余额发送到其他地方。
• 如果在gas 不足的情况下交易执行没有恢复(回滚),合约必须采用强大的安全措施来防止合约被更改。
• 如果不存在子限制,恶意帐户可以通过与其他帐户达成协议来对其他帐户执行拒绝服务攻击。 在计算开始时插入一个大循环,向受害合约发送消息,或任何补救措施,都会使整个交易陷入僵局。
• 要求交易发送方支付gas 费用,而不是合同费用,大大提高了开发人员的可操作性。 以太坊的早期版本通过合约支付 gas,这导致了一个相当严重的问题:每个合约都必须实施“守卫”代码以确保每个传入消息都有足够的以太币供其使用。
耗气量计算具有以下特点:
• 对于任何交易,将收取21000 gas 的基本费用。 这些费用可用于支付运行椭圆曲线算法所需的成本。 该算法旨在从签名中恢复发件人的地址以及存储交易所花费的硬盘和带宽空间。
• 交易可以包括无限量的“数据”。 虚拟机中的某些操作码允许合约允许交易访问此数据。 数据的固定消耗计算为:每个零字节4个gas,每个非零字节68个gas。 出现这个公式是因为合约中的大多数交易数据由一个 32 字节的参数列表组成,其中大部分有许多前导零字节。 这种结构看似效率低下,但由于压缩算法,实际上效率很高。 我们希望这种结构能够取代其他更复杂的严格按照预期字节数包装参数的机制,从而导致编译阶段的复杂性显着增加。 这是三明治复杂模型的一个例外,但由于成本效益比,它也是一个合理的模型。
• 用于设置账户存储的操作码SSTORE的消耗为: 1. 将零值变为非零值时,消耗20,000 gas; 2. 当零值变为零值,或非零值变为非零值时,它消耗5,000 gas ;3。 将非零值变为零值,消耗5000gas,加上交易执行成功后返还的20000gas。 退款金额上限为交易消耗的gas总量的50%。 这样的设置会激励人们清除记忆。 我们注意到,由于缺乏这种激励,许多合约导致存储空间没有得到有效利用,从而导致存储量迅速膨胀; 收取存储费可以带来很多好处,同时不会失去合同一旦建立就永久存在的意义。 确保。 延迟退款机制对于防止拒绝服务攻击是必要的。 攻击者发送一个包含少量gas的交易,循环清空大量存储,直到gas用完,消耗大量验证算力,但实际上并没有清空存储或消耗大量气体。 50%的上限是为了保证获得一定交易gas的矿工仍然可以确定执行交易的计算时间上限。
• 合约提供的消息数据是免费的。 因为在消息调用期间不需要实际复制任何数据,所以调用数据可以简单地看作是指向父合约内存的指针,在子进程执行时不会改变。
• 内存是一个可以无限扩展的数组。 但是每扩容32字节的内存会消耗1个gas成本,不足32字节的会被算作32字节。
• 部分操作码的计算时间极度依赖参数,gas开销计算是动态变化的。 例如,EXP 的开销是指数级的; 复制操作码(例如:CALLDATACOPY、CODECOPY、EXTCODECOPY)的开销为 1+1(每个副本 32 字节)。 这里不包括内存扩展的开销,因为它会引发二次攻击。
• 如果该值不为零,操作码CALL 将额外消耗9000 gas。 这是因为任何价值转移都会导致存档节点的历史存储显着增长。 请注意,实际消耗是6700,在此基础上,我们强行增加了一个自动给接收方的gas值,最小值是2300。这样做是为了让接受交易的钱包至少有足够的gas记录交易。
gas 机制的另一个重要部分是 gas 价格本身所体现的经济性。 在比特币中,默认的方法是收取纯粹自愿的费用,矿工充当看门人并动态设置最低费用。 在以太坊中,交易发送者可以设置任意数量的气体。 这种方式在比特币社区非常流行,因为它是“市场经济”的体现:让矿工和交易者根据供求关系来决定价格。 但是,这种方法的问题是交易处理不遵循市场原则。 Although transaction processing can be thought of as a service provided by miners to senders (which sounds intuitive), in fact every transaction processed by a miner must be processed by every node in the network, so the majority of transaction processing The costs are all borne by third party agencies, not the miners who decide whether to dispose of it.
Currently, because there is a lack of clear information on how miners behave in practice, we will take a very simple and fair approach: a voting system to set the gas limit. Miners have the right to set the gas limit of the current block within 0.0975% (1/1024) of the gas limit of the last block. So the final gas limit should be the median value set by the miners. We hope to use a soft fork to use a more precise algorithm in the future.
虚拟机
The Ethereum Virtual Machine is the engine that executes transaction codes, and it is also the core difference between Ethereum and other systems. Note that the virtual machine should be considered separately from the "contract and message model". For example, the SIGNEXTEND opcode is a function of the virtual machine, but in fact "a contract calls other contracts and specifies the gas limit for sub-calls" is part of the "contract and message model". The design goals of the EVM are as follows:
•Simple: as few and low-level opcodes as possible; as few data types as possible; as few virtual machine structures as possible;
• The result is unambiguous: In the VM specification statement, there is no room for possible ambiguity, and the result should be completely deterministic. Also, the calculation step should be precise so that the gas consumption can be measured;
• Space saving: EVM components should be as compact as possible;
• Expected applications should have specialized capabilities: applications built on the VM should be able to handle 20-byte addresses, and 32-bit custom encrypted values, have modulo operations for custom encrypted, read blocks and transactions Capabilities such as data and state interaction;
• Simple and safe: In order to prevent VMs from being exploited, it should be easy to establish a set of gas consumption cost models;
• Optimization friendly: should be easy to optimize so that just-in-time compilation (JIT) and accelerated versions of the VM can be built.
At the same time, EVM also has the following special design:
• Temporary/permanent storage distinction:
Let's first look at what is temporary storage and permanent storage.
Temporary storage: exists in each instance of the VM and disappears after the execution of the VM;
Permanent storage: Exists in the blockchain state layer.
Suppose the following tree is executed (S stands for permanent storage, M stands for temporary storage):
1. A calls B;
2.B set BS[0]=5, BM[0]=9;
3.B calls C;
4. C calls B.
At this time, if B tries to read BS[0], it will get the data previously stored in B, which is 5; but if B tries to read BM[0], it will get 0, because BM is a temporary storage, and the read When it is fetched, it is a new instance of the virtual machine.
In an internal call, if you set BM[0] = 13 and BS[0] = 17, then both the internal call and the call of C are terminated, and then the external call of B is executed. At this time, when reading M, you will see BM [0] = 9 (this value was set in the last execution instance of the same VM), BS[0] = 17. If B's external call ends, and A calls B again, you will see BM[0] = 0 and BS[0] = 17. The purpose of this difference is: 1. Each execution instance is allocated with memory space, which will not be degraded by loop calls, which makes safe programming easier. 2. Provide an in-memory form that can be operated quickly: because the tree needs to be modified, storage updates are necessarily slow.
• Stack/memory model
In the early days, there were three computing states: stack (stack, a 32-byte standard LIFO), memory (memory, infinitely expandable temporary byte array), and storage (storage, permanent storage). On the temporary storage side, the alternative to stack and memory is the memory-only paradigm, or a hybrid of registers and memory (there is not much difference between the two, registers are essentially a kind of memory). In this case, each instruction has three arguments, for example: ADD R1 R2 R3: M[R1] = M[R2] + M[R3] . The reason for choosing the stack paradigm is obvious, it makes the code 4x smaller.
• word size 32 bytes
In most structures, like Bitcoin, the word size is 4 or 8 bytes. 4 or 8 bytes is too restrictive for storing addresses or cryptographic calculations. If the value is too large, it is difficult to establish a corresponding safe gas model. 32 bytes is an ideal size, because it is enough to store the implementation and address of many encryption algorithms, but it will not be too large to cause inefficiency.
• We have our own virtual machine
Our virtual machines are developed using languages such as java, Lisp or Lua. We think it's worth developing a professional virtual machine because:
1. Our VM specification is much simpler than many other VMs because other VMs pay less for complexity, ie they are easier to get complex; however, every additional bit of complexity in our scheme Sexuality will bring obstacles to intensive development, as well as potential security flaws, such as causing consensus failure, which makes our complexity cost high, so it is not easy to cause complexity;
2. Our VM is more specialized, such as supporting 32 bytes;
3. We will not have complex external dependencies, which will cause our installation to fail;
4. A complete review mechanism can be specific to special security requirements; for external VMs, this is necessary anyway.
• Uses a variable, expandable memory size
The size of pinned memory is an unnecessary limitation, too small or too large is appropriate.如果内存大小是固定的,每次访问内存都需要检查访问是否超出边界,显然这样的效率并不高。
• 栈大小没有限制
没什么特别理由!许多情况下,该设计不是绝对必要的;因为,gas的开销和区块层gas的限制总是会充当每种资源消耗的上限。
• 1024调用深度限制
许多编程语言在栈的深度过大时触发中断比在内存过载时触发中断的策略要快的多。所以区块中gas限制所隐含的限制是不够的。

• 无类型
为了简单起见,可以使用DIV, SDIV, MOD, SMOD的有符号或无符号的操作码代替(事实证明,对于操作码ADD和MUL,有符号和无符号是对等的);转换成定点运算在所有情况下都很简单,例如,在32位深度下,a * b -> (a * b) / 2^32, a / b -> a * 2^32 / b ,+, - 和* 在整数下不变。
VM中某些操作码的函数和作用很容易理解,但也有一些不太好理解,以下是一些特殊的原因:
*• ADDMOD, MULMOD *
大多数情况下,addmod(a, b, c) = a * b % c,但在椭圆曲线算法中,使用的是32字节模数运算,直接执行a * b % c 实际上是在执行((a * b) % 2^256) % c会得到完全不同的结果。计算公式a * b % c 使用32字节空间的32字节值是非常不常见且繁琐。
• SIGNEXTEND
SIGNEXTEND操作码的作用是为了方便从大的有符号整数到小的有符号整数的类型转换。小的有符号整数是很有用的,因为未来的即时编译虚拟机可能会检测长时间运行的代码块,小的有符号整数能加快处理。
• SHA3
在以太坊代码中SHA3作为安全的高强度的hash集合应用非常广泛,通常在使用存储器时需要使用Hash函数来确保安全,以防止恶意冲突,在验证默克尔树和类似以太坊的数据结构时也需要使用到Hash函数。重要的是,与SHA3的相似的hash函数,如SHA256,ECRECVOR,RIPEM160不是以操作码的形式包含在里面,而是以伪合约的形式。这样做的目的是将它们放在一个单独的类别中,如果当我们以后提出适当的“本地扩展”系统时,可以添加更多这样的合约,而不需要扩展操作码。
• ORIGIN
ORIGIN操作码由交易的发送者提供,主要的作用是允许合约退回支付的gas。
• COINBASE
COINBASE的主要作用是:1.如果使用COINBASE操作码,则允许子货币对网络安全作出贡献;2.开放使用矿工作为一个去中心化的经济体,来设置基于子共识的应用以太坊中有几类账户,如Schellingcoin。
• PREVHASH
PREVHASH作为一个半安全的随机来源,允许合约评估上一个区块的默克尔树状态证明,而不需要高度复杂的递归结构“以太坊轻客户端”。
• EXTCODESIZE, EXTCODECOPY
主要的作用是让合约依据模板检查其他合约的代码,甚至是在与其他合约交互前,模拟它们。
• JUMPDEST
当跳转(jump)目的地限制在几个索引时(尤其是,动态目的跳转的计算复杂度是O(log(有效挑战目的数量)),而静态跳转总是恒定的),JIT虚拟机实现起来更简单。于是,我们需要:1.对有效变量跳转目的地做限制;2.使用静态而不是动态跳转的激励方式。为了达到这两个目标,我们定下了以下规则:1.紧接着push后的跳转可以跳到任何地方,而不仅是另一个jump;2.其他的jump只能跳转到JUMPDEST。对跳转的限制是必须的,你可以通过查看代码中的先前操作来决定是静态还是动态的跳转。缺乏对静态跳转的需求是激励使用它们的原因。禁止跳转进入push数据也会加快JIT虚拟机的编译和执行。
*• LOG *
LOG是事件的日志。
• CALLCODE
该操作码允许合约使用自己的存储器,在单独的栈空间和内存中调用其他合约的“函数”。这样可以在区块链上灵活实现标准库代码。
• SELFDESTRUCT
允许合约删除它自己,前提是它已经不需要存在了。SELFDESTRUCT并非立即执行,而是在交易执行完之后执行。这是因为这样做可以恢复那些执行后大大增加了缓存复杂度的SELFDESTRUCT操作码。
• PC
尽管理论上不需要PC操作码,因为所有的PC操作码都可以根据将push操作的索引加入实际程序计数器来代替实现,但使用PC可以创建独立代码的位置(可复制粘贴到其他合约的编译函数,如果它们以不同索引结束,不要打断)。
笔记:
① UTXO: unspent transaction outputs。字面理解是:有效的交易输出,它是比特币协议中用于存储交易信息的数据结构。
② Nonce,Number used once或Number once的缩写,在密码学中Nonce是一个只被使用一次的任意或非重复的随机数值,在加密技术中的初始向量和加密散列函数都发挥着重要作用,在各类验证协议的通信应用中确保验证信息不被重复使用以对抗重放攻击(Replay Attack)。
③ 嵌套数组:创建一个数组,并使用其他数组填充该数组。如数组pets:
var cats : String[] = ["Cat","Beansprout", "Pumpkin", "Max"];
var dogs : String[] = ["Dog","Oly","Sib"];
var pets : String[][] = [cats, dogs];
④ 行程编码(run-length-encoding):一种统计编码。主要技术是检测重复的比特或字符序列,并用它们的出现次数取而代之。(百度百科)
⑤ 布隆过滤器:由Howard Bloom 在1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。(百度百科)
⑥ uncle:A挖出区块后广播途中,B也挖出了区块(过时区块),此时区块链会出现分叉。过时分叉上的区块就叫uncle区块。它不是这个块的父区块,父区块的兄弟区块(平级关系)。
原版的:




